




résumés de texte
La quantité de contenu textuel généré chaque jour augmente à un rythme exponentiel. Un si grand nombre de données est une source précieuse de connaissances qui constitue un vrai challenge à traiter et analyser. La synthèse textuelle automatique est une solution à ce problème, en particulier parce qu’elle peut être appliquée à différents types de documents (c’est-à-dire des e-mails, des sites web, des livres, des tweets…) (cf. Figure 1). L’objectif de cette synthèse est d’analyser les données textuelles afin de présenter les informations les plus importantes à l’utilisateur sous une forme concise et d’une manière adaptée à ses besoins.
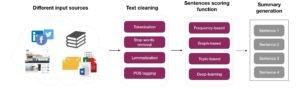
Fig. 1. Pipeline de génération de résumé
Les applications de synthèse d’information en général, et de résumé automatique de texte en particulier, sont variées et s’appliquent à plusieurs secteurs. Voici des exemples :
- Secteur du e-commerce : Les plateformes e-commerce permettent aux utilisateurs d’acheter divers produits et leur donnent la possibilité d’exprimer leurs opinions à l’aide d’évaluations numériques et de commentaires textuels. Analyser et synthétiser ces données peut aider ces entreprises à comprendre les besoins et les attentes de leurs clients, de dégager des tendances et d’assister d’autres potentiels acheteurs dans leur prise de décision.
- Secteur des Médias : Au cours de la dernière décennie, le nombre d’articles de presse en ligne a explosé. Pour les lecteurs, parcourir plusieurs articles, surtout à partir des terminaux mobiles, devient donc pénible et fastidieux. Fournir aux lecteurs des résumés automatiques résout ce problème en présentant les informations les plus importantes sous une forme réduite.
- Secteur financier : Les banques et les assurances produisent quotidiennement des documents internes qui sont fréquemment stockés dans les bases de données en tant que données non structurées. L’utilisation d’un système de génération de résumé permettrait de réutiliser efficacement ces connaissances déjà existantes mais sous-utilisées. Par exemple, dans le cas des contrats juridiques, un tel système peut ajouter de la valeur en résumant un contrat aux clauses les plus risquées, ou en faisant une synthèse comparative de plusieurs contrats a fin de comprendre les points de similitude ou de divergence. Un autre exemple serait l’analyse des documents financiers comme les rapports sur les marchés financiers qui peut aider les analystes à évaluer rapidement une situation financière avant de recommander toute action à leur banque ou à leurs investisseurs.

Fig. 2. Comparaison des deux types de résumés : abstractif et extractif
Nous pouvons diviser les techniques de résumé en deux catégories : résumé abstractif et résumé extractif. Le résumé extractif vise à choisir des parties du document d’origine, comme des phrases entières voire même un paragraphe. Un résumé abstractif paraphrase le contenu du document original tout en prenant en compte la cohésion et la concision du résumé en sortie. La Figure 2 montre un exemple des deux résumés. Le résumé extractif sélectionne les deux phrases les plus importantes du texte original, par contre nous observons qu’il introduit un terme anaphorique « ceci » qui fait référence au problème du grand nombre de données générées. Cela rend le résumé incomplet, d’où la nécessité de revenir au texte d’origine (ce problème peut également se produire lors de la génération de résumés abstractifs). D’un autre côté, un résumé abstractif est capable de paraphraser le texte original, de générer de nouvelles phrases et d’inclure de nouveaux mots comme « companies » et « digest » ce qui rend le résumé plus concis.
Avant de procéder à la génération de résumé, plusieurs étapes en amont sont nécessaires. La Figure 1 en décrit certaines. La première étape est le nettoyage du bruit dans le texte non structuré (par exemple les fautes d’orthographe, la ponctuation, les balises HTML, les URL…). Le résultat de cette étape de nettoyage est un vocabulaire que nous pouvons utiliser comme entrée pour les méthodes de génération de résumés.
Plusieurs méthodes de génération de résumés existent, à savoir des méthodes basées sur les fréquences de mots, les graphes ou même les réseaux de neurones. Récemment, ce sont les modèles d’apprentissage profond (Deep Learning) qui ont atteint les meilleures performances dans ce domaine. Ces modèles apprennent les relations cachées entre les phrases sources et cibles à partir d’un dataset d’entraînement composé de paires document/résumé. Un type de modèles appelé Réseaux Neuronaux Récurrents (RNN) s’est avéré au début extrêmement efficace dans de nombreuses tâches en NLP, car il modélise les phrases comme une séquence de mots connectés les uns aux autres ou les attributs appris sont partagés entre différentes couches. Par exemple, les RNN peuvent apprendre (« mémoriser ») à partir des données d’entraînement que le mot « chien » apparaissant en position t indique que le mot en position t + 1 est « aboie ».
Généralement, un paradigme encodeur-décodeur est utilisé pour générer des résumés textuels abstraits. Plus précisément, le codeur est un RNN qui lit un mot à la fois dans la source d’entrée et renvoie un vecteur représentant le texte d’entrée. Le décodeur est un autre RNN qui génère des mots pour le résumé et qui est conditionné par la représentation vectorielle renvoyée par le premier réseau. Afin de trouver la meilleure séquence de mots qui représente un résumé, un algorithme de recherche en faisceau (beam search) est couramment utilisé.
Les RNN standard créent pour chaque séquence une nouvelle instance du réseau. Plus le nombre de séquences est long, plus le nombre de couches grandit et le réseau se complexifie. Il faudrait donc autant de dérivées à calculer pour chaque mise à jour des poids. Cela rend les calculs plus lents et complexes et introduit aussi le problème d’évanouissement du gradient. Afi n de palier à ces problèmes, les RNN peuvent être implémentés avec des variantes sophistiquées telles que les unités à mémoire court terme étendue (LSTM) et le Gated Recurrent Unit (GRU). De cette manière, ils arrivent à distinguer entre les données importantes à garder et à réinjecter dans le réseau, et les données qui doivent être oubliées.
Au cours des dernières années, les mécanismes basés sur l’attention ont gagné en popularité car ils « se souviennent » de certains aspects de l’entrée plutôt que de coder une séquence entière d’informations d’entrée, sans se soucier de savoir si l’une des entrées est plus importante qu’une autre.
Ces modèles ont par contre montré plusieurs lacunes concernant la tâche de génération de résumé de document : 1) ils sont parfois incapables de reproduire des informations précises à partir du document d’entrée, 2) les résumés générés sont répétitifs et contiennent des informations redondantes. Le premier inconvénient est dû au fait que ces modèles ne sont pas en mesure de gérer efficacement les mots rares et hors du vocabulaire (OOV) car leur représentation en vecteur est mal construite. Le deuxième problème pourrait être dû au fait que le décodeur s’appuie trop sur le mot précédent dans le résumé plutôt que sur des informations à plus long terme. Pour remédier à ces deux lacunes, See et al. [1] ont proposé un réseau pointeur-générateur qui combine implicitement l’abstraction avec l’extraction. Cette architecture peut copier des mots à partir de textes sources via un pointeur pour garantir que les informations factuelles peuvent être reproduites avec précision. Elle peut également gérer les mots hors du vocabulaire et générer de nouveaux mots à partir d’un vocabulaire via un générateur. Le deuxième défaut est résolu en utilisant un mécanisme de couverture qui évite d’avoir des informations redondantes dans les résumés. D’autres heuristiques sont également utilisées pour résoudre ce problème, comme mettre des conditions sur le nombre maximum de fois pour sortir les mêmes mots dans le même résumé.
Pour conclure
Il est vrai que les progrès récents dans le domaine du Deep Learning ont produit des résultats de pointe dans la génération de résumés, par contre le problème n’est pas encore complètement résolu. Les résumés générés peuvent parfois être répétitifs, incohérents ou même biaisés. Il est donc possible d’améliorer ces modèles en créant des algorithmes capables d’atteindre des degrés de précision et d’abstraction plus élevés. Finalement, la compréhension du « raisonnement » des algorithmes de l’apprentissage profond devient indispensable afi n d’apporter plus d’explications aux décisions prises par ces algorithmes ce qui permettrait, entre autres, d’améliorer la qualité des résultats générés et peut-être réduire les biais moraux et éthiques qui sont appris lors de l’entraînement de ces modèles.
Vous pouvez également trouver plus de détails concernant les différentes propriétés, techniques de génération et méthodes d’évaluation de résumés, dans l’article complet en anglais : https://www.aquiladata.fr/understanding-textual-summary-generation/


