




textual summary
The amount of textual content generated everyday is growing at an exponential rate. Such large numbers of textual data is a valuable source of knowledge, unfortunately it becomes impractical for anyone to process all the available information. Automatic textual summarization is a solution to this problem especially because it can be applied to different types of inputs (i.e. documents, emails, websites, books, tweets…) (see Figure 1). The goal of automatic summarization is to process and analyse the textual data, then to present the most important information to the user in a concise form and in a manner sensitive to his needs. For example summarizing financial documents like market reports and financial news can help analysts to quickly evaluate the financial situation before recommending any action to their company or investors.
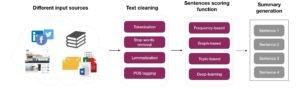
Fig. 1. Summarization generation pipeline
The goal of single document summarization is to generate an abstract summary for a single document. On the other hand, the goal of multi-document summarization is to aggregate information across different documents that are related to the same topic but with different perspectives. Multi-document summarization is more challenging than single document summarization. The first challenge is the coherence of the summary. Coherence measures how much it’s easy or fluent to understand a summary. It is difficult for multidocument summarizers to produce coherent summaries, since it is less straightforward to rely on the order of sentences in the underlying documents than in the case of single- document summarization. The second challenge is that the summary should extract representative sentences from multiple documents, which is not the case of single document summarization.

Fig. 2. Comparison of both types of summaries abstractive and extractive
We can divide techniques of summarization into two categories: abstractive and extractive summarization of a single or multiple documents. Extractive summarization aims to choose parts of the original document such as sentence parts, whole sentence or paragraph. Abstractive summarization paraphrases content of the original document with respect to cohesion and conciseness of the output summary. Fig. 2 shows an example of both summaries. Extractive summary selects the two most important sentences from the original text, but we can observe that it introduces an anaphoric term, « this », that refers to the problem of the big amount of data generated. This makes the summary not self-contained thus the need to go back to the original text (this problem can be found in while generating abstractive summaries as well). On the other hand, abstractive summarization is able to paraphrase the original text, generate new sentences and include new words like « companies » and « digest ».
1 / Summary properties
The first step before developing a summarization system is to specify certain qualitative or quantitative properties, which are related to the specific summarization task and the evaluation method that will be used. Such criteria may be, among others:
- Coverage: Coverage of topics, opinions, or content of the document. Coverage can be on the level of the extracted sentences or on the whole summary. By taking coverage into consideration the information loss might be minimized.
- Readability: Measures how much it’s easy or fluent to understand a summary. It consists of various elements such as the average number of characters and complex words, and the grammatically and well-formness of the sentences in the summary.
- Informativeness: Reflects how much the summary represents the main ideas of the source text. It also represents the amount of information the summary carries. For example, a summary should not contain unnecessary details.
2 / Summary generation methods
In this section we present different methods to generate a summary. Figure 1 describes some steps to clean text from noise (e.g. typos, punctuation, html tags, and urls). The output of this cleaning step is a vocabulary that we can use as input for the summary generation methods. Standard natural language techniques are usually applied to clean noisy textual content. For example « Tokenization » that consists in splitting a given document into small pieces (tokens or lemmas) at the same time as removing certain characters, such as punctuation. Here is an example of tokenization. The output of the sentence « This was a good movie! » is [« this », « was », « a », « good », « movie »]. Depending on the context, documents usually use different forms of the same word, for example, drive, driving, or driven. The goal of « Lemmatization » is to reduce inflectional forms of a word to a common base form. For instance, the verb « driving » will become « drive ».
2/1. Frequency based methods
In extractive summarization, sentences are identified and extracted from the source text and then are concatenated to form a concise summary. Early extractive techniques are based on simple statistical analysis about sentence position, term frequency, or basic information retrieval techniques such as inverse document frequency. The most common measure widely used to calculate the word frequency is TF-IDF. TF-IDF stands for Term Frequency – Inverse Term Frequency, and it ranks higher « distinctive » words, meaning words that are frequent in the input document but infrequent in other documents. The score of a sentence is measured by the sum of the TF-IDF scores of the words it contains. Other features can be used to include sentences in the final summary, i.e. sentences containing proper nouns have greater chances to be included in the summaries. Also sentences containing acronyms or proper names are included. Finally if sentences contain Cue-Phrase features (e.g. « in conclusion », « argue », « purpose », « attempt », etc.) they are most likely to be in summaries. To form a summary, the sentence selection approach can be based on a greedy strategy or on optimization approach to maximize the occurrence of the important words globally over the entire summary.
2/2. Graph based methods
Prior studies have represented text as a graph data structure. For example in the work of Mihalcea et al. [2] the idea was to store words in vertices, and to use the co-occurrence between the words to draw edges. Then they ranked the graph vertices across the entire text using an adapted version of the PageRank algorithm to account for edge weights. The words having a high PageRank score were considered as keywords. Another work of Ganesan et al. [1], focused on highly redundant opinions. The key idea was to use a graph to represent text. They cast the problem of summarizing the text, as one of finding appropriate paths in the graph using the position of the words and the number of occurrences of the sentences.
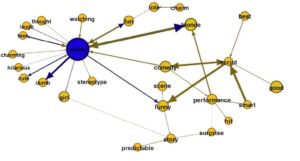
Fig. 3. An example of a sub-graph generated from the « Legally Blonde » movie.
Text can also be modeled as a graph of sentences where each node is a sentence. The most used method to compute similarity is cosine similarity with TF-IDF weights for words. Sometimes, instead of assigning weights to edges, the connections between vertices can be determined in a binary fashion: the vertices are connected only if the similarity between the two sentences exceeds a pre-defined threshold. Sentences that are related to many other sentences are likely to be central and would have a high weight for selection in the summary. Figure 3 represents sub-graph generated from the « Legally Blonde » IMDB movie reviews. The nodes represent single words in the reviews whereas the edges represent word co-occurrences in the text, the direction of the edges represents the sentences structure. The Edge thickness represents the similarity score of the related words, whereas the node size represents the word frequency in the set of reviews. We can see that reviewers think that « Legally Blonde » is a « comedy movie » and it has a « smart / funny script ».
2/3. Deep learning methods
DL models learn hidden relationships between source and target sentences from a training set composed by document/summary pairs. One type of models called Recurrent Neural Networks (RNNs) have been proven to work extremely well in many NLP tasks. Why? simply because it models sentences as a sequence of words that depend on each other, and where learned features are shared across different positions of text. For example RNNs can learn (« memorise ») from the training data that the word « barking » appearing in position t gives a sign that the word in position t+1 is « dog ».
Usually an encoder-decoder paradigm is used to generate abstract textual summaries. More specifically, the encoder is an RNN that reads one token at a time from the input source and returns a vector representing the input text. The decoder is another RNN that generates words for the summary and it is conditioned by the vector representation returned by the first network. In order to find the best sequence of words that represent a summary, a beam search algorithm is commonly used. The RNNs of the encoder and decoder can be implemented with sophisticated variants such as Long-Short Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks. In the recent years, attention-based mechanisms gained in popularity as they « remember » certain aspects about the input rather than encoding an entire sequence of input information without regards to whether or not any of the inputs are more important than another.
For the task of summarizing documents into multi-sentence summaries, these models showed several shortcomings:
1) They are sometimes unable to reproduce accurate information from the input document.
2) The generated summaries are repetitive and contain redundant information.
The first shortcoming is due to the fact that these models are unable to handle efficiently rare and out-of- the-vocabulary words because their word embedding is poorly constructed. The second problem might be due to the fact that the decoder relies too much on the previous word in the summary rather than longer-term information. To tackle both shortcomings, See et al. [3] proposed a pointer-generator network that implicitly combines the abstraction with the extraction. This architecture can copy words from source texts via a pointer to ensure that factual information can be reproduced accurately. It can also handle OOV and generate new words from a vocabulary via a generator. The second shortcoming is solved using a coverage mechanism that avoids having redundant information in the summaries. Other heuristics are also used to solve this problem, like putting conditions on the maximum number of times to output the same n-words in the same summary.
3/ Evaluation methods
Similar to generating textual summaries, evaluating summaries is also a challenging problem. The challenge comes from the subjectivity of deciding on the quality of a summary as the notion of « importance » is different from one user to another. Another crucial aspect is to determine the goal of the summary. Is it to help users make faster decisions? or is it to inform them about the main topics or concepts in the original text document? The answer to each summary goal requires a different evaluation strategy. For example, in the first scenario the evaluation should include a user study that measures the time it takes users to make a decision after reading a summary. In the second scenario, a coverage metric should be used. Existing evaluation criteria consider the intrinsic aspects of a summary, such as its coherence, conciseness, grammaticality, and readability. Other extrinsic evaluation criteria measure, for example, whether a reader is able to comprehend the content of a summary.
3/1. Intrinsic evaluation
In this case, evaluation is quantitative and uses metrics such as precision or recall. The most common automatic evaluation for summarization systems is ROUGE (Recall-Oriented Understudy for Gisting Evaluation). First, human assessors are asked to read the original textual documents and to produce a summary (usually called reference or gold standard summary). Then the automatically produced summaries are compared with the gold standard summaries. More specifically, ROUGE works by measuring n-gram overlap between gold standard summaries and system summaries. With this it can measure topic relevance and in some cases readability especially when using higher order grams (ROUGE-N). The used formulas are the following precise which ROUGE:
![\[precision = \frac{| S_{ref} \cap S |}{|S|}\]](https://www.aquiladata.fr/wp-content/ql-cache/quicklatex.com-59ef872cf5140d3ca3a962dbf1a46aff_l3.png "Rendered by QuickLaTeX.com")
![\[recall = \frac{| S_{ref} \cap S |}{|S_{ref}|}\]](https://www.aquiladata.fr/wp-content/ql-cache/quicklatex.com-cacd750e764f98192f0007213a92f754_l3.png "Rendered by QuickLaTeX.com")
Let’s suppose that our system generated this sentence as a summary: « The Silence of the Lambs is a scary movie », and that the human reference summary is « The Silence of the Lambs is a very scary movie ». The precision and recall are going to be both high (respectively 1 and 0.8 ) as there is a high overlap between both summaries.
The problem with this approach is (1) it is usually difficult to make people agree on what constitutes a « gold » summary. (2) ROUGE doesn’t take into consideration the semantic similarity between words, for example if the system generates the following summary « Silence of the Lambs is a frightening film » and if the gold standard summary is « Silence of the Lambs is a very scary movie », than the ROUGE score will be low even if both sentences contain the same information. (3) higher order rouge n-gram ROUGE-N  1 should be used with caution as it does not cover different writing styles.
1 should be used with caution as it does not cover different writing styles.
3/2. Extrinsic methods
Finally, using standard evaluation metrics such as precision and recall won’t answer questions such as: Did the summary help users in their decision making process, or did it inform readers about the most important information of a topic? That’s when extrinsic evaluation methods such as user studies and surveys come in handy. There are many challenges involved in designing a user study such as asking the right research questions, selecting users that would take the user study, creating surveys that contain precise and understandable questions that can have quantitative answers, avoid including any kind of bias, etc…
Usually, combining both extrinsic and intrinsic evaluation types gives a better evaluation of summarization models as they evaluate both the performance of the model as well as the perceived usefulness of its outcomes by users.
4/ Conclusion
It is true that the recent advances in machine learning and especially deep learning produced state-of-the-art results in summary generation, but this problem is not completely solved yet. The generated summaries can be sometimes repetitive, unnatural or ungrammatical. So there is still room for improvement in creating powerful models that are able to reach higher degrees of abstraction, as well as explaining RNNs to uncover what exactly these models are learning from text.


