Les travaux de G.Hinton publiés en 2006, puis le succès du modèle AlexNet en 2012 au Challenge ImageNet, ont réveillé, au sein de la communauté scientifique, l’intérêt pour le Deep Learning. Il avait été délaissé depuis le milieu des années 1970, on parle même pour cette période « d’hiver de l’intelligence artificielle ». La disponibilité croissante de grandes quantités de données, couplée à l’augmentation de la puissance de calcul (cluster de calculs, GPU, TPU), a permis de grandes avancées dans le domaine de la Computer Vision. De la classification d’images, au transfert de style, en passant par la détection d’objets, les applications au sein des entreprises se multiplient. Dans cet article, nous présentons plus spécifiquement les réseaux de neurones convolutionnels, utilisés pour les tâches de classification d’images et de détection d’objets.
Classification d’images
Exemple MNIST
Pour présenter les CNN, nous allons nous appuyer sur le data set open source Fashion-MNIST (publié par l’équipe de recherche de Zalando dans le but de remplacer le data set MNIST). Ce data set est composé de 70 000 images représentant des vêtements (60 000 pour le training set et 10 000 pour le testing set). Les images sont fournies en dimension 28 x 28 avec une intensité de gris pour chaque pixel allant de 0 à 255. Chaque image peut donc être représentée sous forme d’un vecteur de 28×28 = 784 variables. Chaque image appartient à une classe parmi 10 catégories (pull, pantalon, chaussures…).

Figure 1 : Exemple d’images du dataset Fashion MNIST
Du Machine Learning au Deep Learning
Notre objectif sera ainsi de prédire la classe d’une image à partir de son contenu. Mathématiquement, cela revient à estimer une fonction F permettant de réaliser un mapping entre les inputs X et l’output Y :
(1) 
avec:
Y  une classe parmi les dix catégories. Elle représente notre variable d’intérêt que l’on cherche à prédire.
une classe parmi les dix catégories. Elle représente notre variable d’intérêt que l’on cherche à prédire.
X les 784 intensités de pixels. Elles représentent les variables explicatives de notre modèle.
Une première approche serait d’utiliser un algorithme de Machine Learning « classique », comme la régression logistique ou bien une forêt aléatoire. Bien que ces approches obtiennent des résultats relativement corrects, ce type d’algorithmes ne pourra pas se généraliser aux images dont l’item se retrouverait dans un coin de l’image plutôt qu’au centre de celle-ci. En d’autres termes, le caractère spatial des éléments caractéristiques de certaines catégories n’est pas pris en compte (exemple : les manches pour un pull).
On s’aperçoit rapidement que l’on a besoin d’un algorithme capable de détecter des formes relatives indépendamment de leur position dans l’image: c’est ce que permettent les Convolutionnal Neural Networks (CNN). Yann LeCun est un des premiers à appliquer ce type de réseau de neurones à grande échelle, pour détecter les montants sur les chèques dans les années 1990. Pour illustrer un CNN, on prend l’exemple de son réseau LeNet-5 :
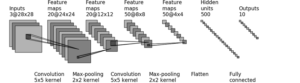
Figure 2 : Architecture du réseau LeNet-5 de Yann LeCun
Un CNN classique alterne majoritairement deux types de couches :
- Couches avec filtre convolutionnel : on réalise un produit entre un filtre (un tableau à deux dimensions dont les poids seront ajustés lors de l’apprentissage) et l’input de la couche. Ce filtre est généralement de dimension 3×3 ou 5×5. La multiplication de ces couches au sein du réseau va permettre d‘extraire des features de plus en plus complexes qui permettront in fine de prédire une classe d’appartenance pour l’item présent dans l’image. C’est pourquoi on parle « d’apprentissage profond ».
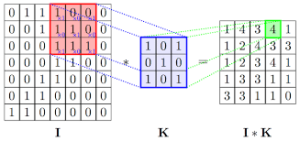
Figure 3 : Principe de la convolution
- Couches avec pooling : elles permettent un undersampling qui va compresser la dimension de l’image et réduire le coût computationnel des couches suivantes. En général on utilise une fonction maximum ou moyenne.
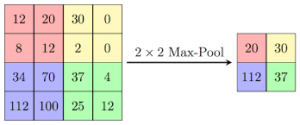
Figure 4 : Principe du max pooling
Sur la figure 2, on constate une succession de couches convolutionnelles immédiatement suivies d’une couche de pooling, ce qui est caractéristique des CNN. Les dernières couches aplatissent les features via une couche Flatten avant d’enchaîner avec des couches dense (FC pour Fully Connected) La dernière couche applique une fonction softmax, afin de déterminer la classe de l’image parmi les dix catégories. Ces dernières couches rappellent la structure d’un perceptron multi-couches.

Table 1 : Résultats des prédictions sur Fashion MNIST
Sur le benchmark ci-dessus, on constate effectivement un boost en terme de performance prédictive sur les réseaux de neurones profonds, par rapport aux algorithmes de Machine Learning classique.
Mais que se passe t-il réellement au sein d’un réseau de neurones convolutionnel ?
Lors de la phase d’apprentissage, les poids des différents filtres convolutionnels vont s’ajuster de sorte que le réseau converge vers la détection d’élements au sein de l’image, qui lui permettront de prédire in fine la bonne catégorie.
On prend ici l’exemple d’une image d’un pull pour observer sa propagation à travers un réseau de type CNN.
On constate que les premières couches restent encore visuellement compréhensibles par l’oeil humain, tandis que les couches supérieures sont caractérisées par un plus haut degré d’abstraction (figures 5 et 6). Néanmoins, on s’aperçoit dans l’exemple du pull que certains filtres du réseau s’intéressent particulièrement aux manches de celui-ci, ce qui lui permettra de le différencier par rapport aux autres vêtements.

Figure 5 : Première couche du CNN

Figure 6 : Deuxième couche du CNN
Détection d’objets dans des images
Les use-cases reposants sur des modèles de détection d’objets se sont beaucoup développés dernièrement : comptage d’objets pour l’analyse du trafic routier, détection des panneaux de signalisation pour la voiture autonome, détection de défauts sur infrastructure… L’objectif ici n’est plus de classifier une image, mais de détecter les objets au sein de celle-ci, en dessinant un rectangle (on parle de bounding box) entourant le plus précisément les objets présents.
De nombreux algorithmes ont déjà vu le jour : YOLO, R-CNN, Fast R-CNN, Faster R-CNN, SSD, RetinaNet… Dans cette partie, nous faisons un focus sur la version 3 du modèle YOLO (développé par Joseph Redmond et al. de l’Université de Washington), car il a l’avantage de pouvoir tourner en temps réel sur des flux vidéos, tout en gardant une bonne performance prédictive. Le graphique suivant montre bien l’arbitrage entre performance prédictive et temps d’exécution des algorithmes.
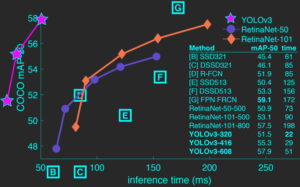
Figure 7 : Performance prédictive Vs. temps d’exécution au moment de la prédiction
Le principe du modèle est de ne parcourir l’image qu’une seule fois, en la faisant passer à travers un réseau de neurones profonds (d’où le nom de You Only Look Once), par opposition aux méthodes dites de regions proposal (notamment utilisées par les modèles basés sur R-CNN).
Le modèle peut se décomposer en deux grands blocs :
- Première composante : La version 3 de YOLO est composé d’un premier CNN de 53 couches appelé Darknet53. Il a été pré-entrainé par les mêmes auteurs sur le data set ImageNet (tâche de classification parmi 1000 classes). Ici, l’idée pour les auteurs est d’appliquer une méthode de tranfert learning. Cette méthode permet de s’appuyer sur un modèle pré-entraîné sur une tâche semblable à la nôtre, pour pouvoir réaliser un apprentissage qui va converger plus rapidement. Les images sont divisées en une grille de cellules (13×13, 26×26 et 52×52). La cellule chargée de détecter l’objet est la cellule contenant le centre de l’objet.
- Deuxième composante : Les auteurs empilent un second réseau de 53 couches très proche du premier, à l’exception des dernières couches. La dernière couche du réseau est de dimension NxN x 3 x [(nb de classes + 1 ) + 4 ]. Lors de l’apprentissage du modèle, les poids de ce second réseau seront ajustés aux données du training set, contrairement aux poids du premier réseau qui seront fixés (principe du transfert learning).
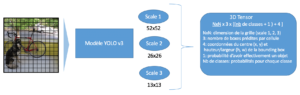
Figure 8 : Dimension des outputs du modèle YOLO v3
La dernière version du modèle a mis l’accent sur deux points principaux :
- Augmentation du nombre de couches du réseau,
- Implémentation de trois échelles de bounding boxes, afin de détecter des objets plus petits.
Ce type d’algorithmes détecte en général plusieurs bounding boxes qui se chevauchent pour un même objet. Les auteurs appliquent donc une méthode dite de Non Max Suppression, afin de ne garder que les bounding boxes les plus significatives.
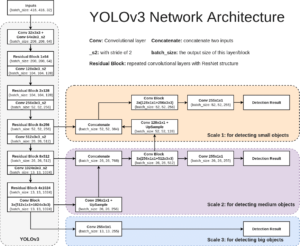
Figure 9 : Architecture globale de la version 3 du modèle YOLO
Application au sein du Data Lab d’Aquila Data Enabler
Au sein du Data Lab d’Aquila Data Enabler, nous avons appliqué cette version de YOLO avec pour objectif de détecter le logo de l’entreprise sur un flux vidéo en temps réel.
Nous avons suivi les étapes suivantes :
- Récupération de photos du logo de l’entreprise dans différents contextes.
- Labélisation des images à la main.
- Data augmentation, afin d’accroître la volumétrie et rendre plus consistant notre jeu de données.
- Apprentissage de YOLOv3 sur les données du data set PASCAL VOC (20 classes d’objets) + les données augmentées de la classe du logo Aquila.
- L’apprentissage a duré quelques heures en utilisant un GPU 1080ti au sein du lab d’Aquila.

Figure 10 : Détection du logo Aquila lors d’un salon