




Vous voulez comprendre et apprendre la mise en production de modèle de Data Science et d’IA ? Vous êtes au bon endroit !
Retrouvez toutes nos autres videos sur notre chaîne YouTube.
Pendant les deux dernières décennies, l’arrivée des nouvelles familles d’algorithmes provenant du domaine Data Mining et les nouvelles puissances de calcul permettant d’entraîner des réseaux profonds contenant des centaines de millions de paramètres ont révolutionné le domaine de l’IA. Cette révolution, initialement adoptée par les chercheurs, s’est rapidement propagé à quasiment tous les secteurs de l’industrie. En effet, les nouveaux algorithmes mentionnés ci-dessus et l’explosion du domaine “Big Data” ont permis d’imaginer de nombreux nouveaux cas d’usage.
L’importance de la donnée a donc pris de l’ampleur et les entreprises ont commencé à la valoriser et à la stocker sous toutes ces formes. La promesse était séduisante : le couplage de la donnée et des algorithmes permet de répondre de manière efficace aux problématiques métier.
Afin de pouvoir répondre à cette grosse demande de cas d’usage dans l’industrie, les experts de la Data Science, initialement présents uniquement dans le monde de la recherche académique ont été recrutées au sein des entreprises afin de constituer des équipes en charge d’évaluer la faisabilité des cas d’usage. Le domaine de la Data Science est donc née avec une communauté d’experts hautement qualifiés ayant des compétences très spécifiques en mathématiques, statistiques et programmation. Dans un premier temps, les Data Scientists sont en charge d’apporter une réponse sur la faisabilité d’un cas d’usage via l’exploration de la donnée (ce qui parfois dérive de manière positive sur la découverte des nouveaux cas d’usage). Ensuite, ils se chargent de la conception et l’évaluation d’algorithmes de Machine Learning à travers un ensemble de métriques, dans la plupart de cas, définies par le métier.
Les études de faisabilité se réalisent souvent sous la forme de PoCs (Proof of Concept study) dans lesquelles on utilise un sous ensemble de la donnée afin d’accélérer la réponse. Ces études ont fait l’objet de grosses dépenses dans l’industrie. Pour différentes raisons, certaines ont échoué (données non suffisants, cas d’usage non adaptées ou mal définies, prise en main de sujets par de personnes étranger au domaine de la Data Science, etc.), tandis que d’autres ont réussi à montrer leur capacité à répondre aux problématiques. Pour ceux qui ont réussi, la question qui se pose maintenant est : Comment pouvoir mettre à disposition des équipes métier les algorithmes développées par les Data Scientists ?
La Data Science étant un champ relativement nouveau, les professionnels ne venant pas du monde de sciences computationnelles ne maitrisent pas le spectre complet de compétences nécessaires pour industrialiser un produit. En effet, construire un modèle de Machine Learning n’a rien à voir avec le fait de le rendre scalable et maintenable. Pour l’un c’est un problème mathématique tandis que pour l’autre c’est un problème d’ingénierie. De ce fait, nait le besoin de rapatrier les compétences des domaines IT pour lesquels les processus de déploiement d’applications sont déjà bien standardisés. Pour certains secteurs de l’industrie, le domaine Big Data n’est pas si nouveau. Dans ce cas, les déploiements de codes applicatifs comme ceux des ERP (enterprise resource planning) et d’autres produits IT sont déjà dans le marché et fonctionne à l’échelle depuis un moment.
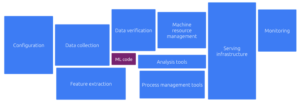
Fig. 1 : Taille relative du code pour les différents composants fonctionnels d’un produit ML. On observe que la quantité du code lié à la génération/utilisation d’un modèle ML reste relativement petite en comparaison avec le reste des composants.
Aujourd’hui, à cause de ce besoin, les Data Labs sont composées par des nombreux spécialistes avec des compétences très diverses. Cela permet de concentrer l’ensemble de compétences nécessaires pour rendre un produit ML industrialisable. Parmi les plus importantes, on peut nommer : les DevOps (appelés MLOps quand ils prennent en main les spécificités d’un produit ML), les ingénieurs Data, les ingénieurs d’infrastructure, les architectes de software et les développeurs back/front/full stack.
Cette structure créer des nouveaux challenges. Par exemple, comment faire communiquer les équipes de Data Science avec les professionnels de l’IT pour qu’ils puissent établir ensemble les processus nécessaires pour imbriquer leurs modèles mathématiques dans des produits ML robustes, scalables et ergonomiques ?
La réponse est qu’ils doivent impérativement établir une étroite communication entre eux car ces équipes sont composés d’une multitude de compétences et donc peuvent aborder une problématique avec différents points de vue. Pour aider la mise en place de cette communication, il faut établir clairement la définition des besoins fonctionnelles dès le départ. Cela permet de donner un périmètre précis à chaque intervenant. Pour résumé, il est primordial de faire le nécessaire pour que les échanges entre les acteurs soient les plus rapides et les plus claires possibles.
Un autre challenge important est le suivi des projets. En effet, il est difficile de fixer l’ordre d’intervention des spécialistes à cause de dépendances très complexes. Il est donc souhaitable que les chefs des projets aient une connaissance très approfondie du métier afin d’optimiser au mieux les temps de travail de chaque intervenant. Il faut également garder en tête que la mise en production d’un produit ML est un ensemble de processus itératifs et que l’ordre dépends du cas d’usage. Concernant les méthodologies de suivi de projets, elles doivent parfois être adaptées. De même, les Backlogs doivent être revues pour chaque profil afin d’établir les Road Maps nécessaires.
Ici on vous propose plusieurs points essentiels à établir avant de démarrer les travaux d’industrialisation d’un produit de ML.
1. Obtenir des informations sur l’environnement cible
Un des points importants sur lesquels les Data Scientists n’ont souvent pas de visibilité est l’environnent cible sur lequel le produit sera déployé en production. Même si aujourd’hui les choses commencent à se simplifier avec l’apparition de fournisseurs de Cloud, certains secteurs comme ceux des finances ou de la santé utilisent souvent des infrastructures avec des composants figés ou parfois même abandonnés. Ainsi, ils sont souvent incompatibles avec les développements fait par les Data Scientists. Durant mon expérience en tant que consultant, j’ai vu plusieurs projets échouer seulement parce que les équipes en charge de mettre le produit en production étaient isolées des équipes de Data Scientists. À cause de cette non-communication, la mise en production du produit reste bloquée sous prétexte que les outils utilisés pour la construction du modèle ne sont pas compatibles avec leur plateforme. Pour les équipes qui possèdent la possibilité de travailler sur le Cloud, les choses se facilitent énormément. Notamment grâce aux services managés et aux avancées du ‘code as infra’, il n’est pas difficile d’instancier des machines avec un environnement très spécifique aux projets ML et de déployer les applications à travers les orchestrateurs de conteneurs. Cependant, si l’environnent reste quand même complexe, il y aura toujours un coût associé à la production de l’infrastructure as code. En parlant de coût, il est aussi important de fixer un budget. Cela permettra de contraindre le niveau de choix technologiques afin de choisir les outils/services managés qui seront utilisés lors de la mise en production.
2. Définir le niveau de scalabilité du produit
Une fois que les caractéristiques de notre environnement cible ont été établis, il faut faire (si cela n’a pas été déjà fait) une étude de faisabilité sur l’utilisation des algorithmes développés lors de l’étape du POC (ou équivalent) vis-à-vis de la volumétrie des données. Autrement dit, est-ce que nos algorithmes seront capables de tourner sur l’ensemble de données qu’on utilisera dans l’environnement de production et tout cela dans un temps raisonnable ? Bien sûr, cela dépend du cas d’usage et de la durée de vie des objets du système ML. D’après mon expérience, quand la scalabilité n’est pas pris en compte dès le départ, on est souvent obligé de recoder la plupart des briques liés au traitement de données. Pourquoi ? Parce que la plupart de grosses volumétries sont traités à travers des outils Big Data qui tournent dans un environnement distribué (données et puissance de calcul réparties sur plusieurs machines). Les abstractions utilisées (API programmatiques) sont souvent très différentes de celles données nativement par le langage et nécessite donc une maitrise importante, autant coté algorithmique que coté best practices. Heureusement comme dit précédemment, les équipes Data commencent à mieux interagir entre elles et les besoins des Data Scientists sont mieux compris par les ingénieurs Data. Cela donne lieu à des nouveaux outils qui permettent une utilisation plus simple de ces abstractions. Il existe des architectures différentes que celles des environnements distribués : les micro services. Ces derniers sont souvent utilisés lors de l’inférence (l’utilisation de notre modèle une fois qu’il a été construit et exposé). On peut aussi s’en servir quand les services peuvent être déployés de manière indépendante (c’est le cas pour certains cas d’usage lors de l’inférence) et sont très simples à scaler grâce aux outils d’orchestration.
3. Établir la durée de vie des objets et planifier le versioning
Il est essentiel de définir le cycle de vie des composants de nos produits. Par exemple, le modèle doit être réentraîné tous les mois, le code applicatif toutes les semaines, etc. Les composants pour lesquels le cycle de vie est diffèrent doivent impérativement être versionnés et séparés avec un déploiement indépendant.
Un autre point important mais parfois fastidieux est la gestion des dépendances entre les composants. Pour ce faire, des outils sont disponibles avec des fonctionnalités de packaging. De plus, le contrôle de versions est important avec n’importe quel logiciel déployé dans un environnement de production. Les produits ML ne font pas l’exception, les chaines traitent souvent de données massives avec des étapes très complexes. En plus, en fonction du cas d’usage, nous pouvons être menés à devoir choisir entre plusieurs modèles, optimiser des hyperparamètres, réduire l’espace des variables etc. Si les résultats de nos recherches sont reproductibles, cela permet d’une part de mieux partager les avancées parmi les équipes Data et d’autre part de pouvoir assurer que toutes les versions du logiciel qui ont permis d’arriver à un résultat peuvent être déployées à nouveau et à n’importe quel moment (utile quand il y a un problème avec un nouveau modèle, une modification avec la chaine de traitement, etc.). C’est pour cela que nous avons besoin des outils dits de tracking pour gérer et suivre les caractéristiques des objets impliqués. La mise en place de ces outils permet d’économiser le temps nécessaire pour reproduire les expériences. Sur les objets à versionner, les plus importants sont : le code (plusieurs types : Modélisation, applicatif, inférence, infrastructure), la donnée (les métadonnées nous permettent de décrire les caractéristiques de la donnée et donc reconnaître de potentielles sources d’erreurs pour nos modèles), les modèles (objets centraux de nos systèmes construits à partir de la donnée traitée avec un ensemble de paramètres et hyperparamètres), les chaînes de traitement et les unités logiques de notre système (décrivent les étapes et le lien entre le code et la donnée, permettant aux modèles d’être générés et propagés jusqu’à l’utilisateur).
4. Quelle stratégie d’exposition et déploiement pour notre modèle et son code applicatif
Nous pouvons exposer notre modèle de différentes manières, cela dépend énormément du cas d’usage et de la définition fonctionnelle du code applicatif. Voici une liste des plus courants :
- Offline. Sur ce paradigme le modèle n’est jamais exposé à l’utilisateur final. Le modèle tourne à partir de données disponibles sur les bases de données et les résultats sont exposées après traitement de manière directe à l’utilisateur final. Un exemple de ce type d’exposition est le moteur de recommandation de Netflix ou l’utilisateur voit les recommandations exposées de manière directe dès qu’il se connecte sur son compte.
- Model-as-a-Service. Exposer un modèle à travers des API web reste le paradigme le plus courant. Sur ce type d’exposition l’API contient un ou plusieurs endpoints. Un endpoint est un point d’accès à l’interface du code applicatif sous la forme d’une adresse (e.g. https://myserver/mymodel/predictions). Le modèle est déployé sous forme de (micro)services lesquels peuvent être déployés de manière indépendante. Les clients font de requêtes du types POST ou GET sur les endpoint pour envoyer/recevoir les données/résultats.
- Online Model-as-a-Service. Sur ce pattern, le modèle apprend directement des données envoyées par les utilisateurs. Il se met à jour à partir d’un certain nombre de requêtes (minimum 1) qui contient des inputs pour l’entrainement du modèle. Un des avantages de cette technique est qu’il n’y a plus besoin de réentraîner le modèle car il est tout le temps à jour. Cette technique est souvent associée avec les algorithmes de réseaux profonds. Cependant des adaptions existe aussi pour de méthodes plus traditionnelles comme les modèles ensemblistes.
Les stratégies de déploiement sont importantes pour éviter de surprises couteuses et les erreurs indésirables. Comme nous avons vu, les erreurs peuvent être silencieuses et les changements dans la version du modèle ou dans d’autres composants doivent être validés de manière rigoureuse. Il existe des stratégies comme celle du ‘Shadow mode’ qui permet d’avoir un deuxième modèle ou composant déployé en production sans que ce dernier interagisse avec les utilisateurs (les données fournissent par l’utilisateur déclenche les actions du deuxième modèle mais ceci est transparent pour l’utilisateur). De cette manière, il est possible de valider les sorties de ce modèle (deuxième) ou composant caché sur une période importante du temps avant de basculer vers un mode où les utilisateurs peuvent l’utiliser. Il existe d’autres stratégies comme par exemple celle du type ‘canary’ où on va utiliser le modèle ou composant sur un petit sous-ensemble des utilisateurs.
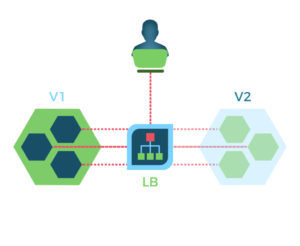 Fig. 2 : Illustration du déploiement du type shadow. Dans ce type de déploiement une deuxième version du modèle est opérationnelle de manière transparente pour l’utilisateur.
Fig. 2 : Illustration du déploiement du type shadow. Dans ce type de déploiement une deuxième version du modèle est opérationnelle de manière transparente pour l’utilisateur.
5. Valider notre modèle une fois mis en production
Le monitoring de modèles de Machine Learning fait référence à la manière dont on suit et comprend la performance d’un modèle au cours du temps dans un environnent de production (données de production). D’habitude, nous utilisons des métriques au cours du temps pour voir à quel point notre modèles se comportent normalement ou, au contraire, anormalement dans l’environnement de production. Un monitoring mal conçu peut donner lieu à des modèles incorrects qui tournent en production, réduisant la valeur de projets ML. Le monitoring donne donc les métriques réelles qui nous permettent de comparer plusieurs modèles déployés (en utilisant des approches tels que le shadow mode). Il peut également être utilisé dans la chaine des boucles de feedback pour interpréter nos modèles.
Mettons tout ensemble : CI / LC / DC
Nous avons déjà analysé quelques points à définir avant de se lancer sur la mise en production d’un projet ML. Maintenant, parlons des pratiques qui nous permettent d’automatiser tout le processus de production.
- L’intégration continue (CI) consiste à automatiser l’intégration de changements du code fait par plusieurs contributeurs dans un seul projet de software. C’est une des principales pratiques du domaine DevOps. Elle permet aux développeurs de logiciels de merger les changements du code dans le répertoire centralisé où l’application sera construite et de lancer des tests automatisés qui permettront de valider les changements de code avant intégration. Un outil de contrôle de code source est un des piliers des processus CI. Ce système de contrôle de versions est associé à d’autres outils pour assurer la qualité de tests et la conformité du code.
- La livraison continue (LC) est une approche ou les équipes libèrent des produits de qualité de manière fréquente et programmée. La livraison continue part d’un répertoire de code et mets à disposition de manière automatique une version prête à tourner dans un environnement de production. Cette pratique permet d’assurer que le code est toujours prêt pour faire une ‘release’. Il est fortement conseillé de mettre à jour le système en production pour assurer que la portée des changements ne soit pas trop importante.
- Le déploiement continue permet aux nouvelles modifications d’être mises dans le répertoire de code source. Ainsi, l’application est automatiquement déployée en production une fois les tests validés. Cela implique une pression plus forte sur les équipes en charge de la mise en place de tests. L’intérêt du déploiement continue est que cela peut accélérer les boucles de feedback entre les utilisateurs et les project owners / équipes dev.

Fig. 3 : La CI/CD permet de faire le pont entre les équipes dev et le gens du métiers qui utilisent les solutions ML.
Conclusion
La valeur de la Data Science ne se trouve pas uniquement dans l’amélioration des performances analytiques mais aussi dans la capacité à exécuter ces analyses en les rendant disponibles sur demande aux utilisateurs avec un niveau de détail jamais vu auparavant. La seule manière d’accomplir cela est de réduire le coût de la mise en production de projets de Data Science à travers l’automatisation.
Une mise en production d’un projet de Data Science ne concerne pas uniquement le déploiement, la disponibilité et le temps de réponse du code applicatif. La Data Science utilise des techniques complexes (parfois sur des données massives) afin de produire des modèles qui dans la plupart des cas serviront aux équipes métiers pour prendre des décisions importantes. Il est donc important de pouvoir valider chacune des étapes avant la production du modèle et d’en voir l’évolution au cours du temps.
Le déploiement de modèles de Machine Learning correspond au moment où le modèle deviendra fonctionnel dans un environnement de production. C’est le moment où les modèles de Machine Learning commence à apporter de la valeur, c’est donc l’étape cruciale de la mise en production.
L’intégration continue, la livraison et le déploiement continue sont les trois étapes d’une chaine automatisée de développement logiciel. C’est ce qu’on appelle une chaine de traitement DevOps. Une telle chaine permet de rendre une idée fonctionnelle grâce à l’automatisation complète.


